
Тег: все эти ваши компьютеры
Сегодняшний рассказ — на мои любимые темы: как заставить роботов работать за людей, и как победить неумолимые корпорации с помощью их же инструментов
Сегодня расскажу про суровое, простое и полезное как топор в лесу кэнк-поделие, на разработку и запуск которого в пром ушло меньше часа времени

Одной из целей при прохождении курса по devsecops для меня было более глубокое и детальное погружение в контейнеризацию и безопасность в ней...
Завершил обучение на курсе «Внедрение и работа в DevSecOps» в OTUS




Двадцать пять лет назад, испытывая потребность в закуске и стаканчиках, мы студентами решили купить в макдачной гамбургеры, попросив заодно стаканы воды

Обновил движок блога до актуальной версии, а заодно победил старую проблему. Эгея умеет вписывать в вёрстку иллюстрации по ширине, но когда вставляешь в пост вертикальную фотку в большом разрешении




Больше 10 лет пользуюсь дома и на работе одной и той же моделью клавиатуры и мыши Logitech MK270. Недавно один из комплектов, на работе, вышел из строя и я попросил выдать мне новый

В последнее время всё чаще сталкиваюсь с необходимостью использовать в powershell вызовы системного API для реализации функционала, под который нет готовых командлетов
Только ленивый ещё не оттоптался на теме наивности ИИ, когда нейросеть отказывается отвечать на какие-то запретные темы, но выдает ответ, если его по-другому сформулировать



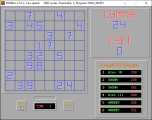
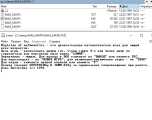
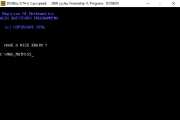

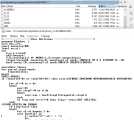
Так сложилось, что несмотря на профильное образование, профессиональным программистом я так и не стал...
Несколько лет использую в работе сервис isDayOff, который позволяет проверить дату на принадлежность к нерабочему дню, согласно официальным указам и распоряжениям
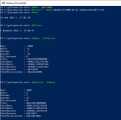
Авторы Powershell, с одной стороны, многое в своём творении придумали системно и логично. С другой стороны, постоянно натыкаешься на странности, объяснения которым в области логики не найти...
Цикл заметок о сетях в Kubernetes от Mark Betz переводился на хабре несколькими участниками. Поэтому в нормальный единый цикл заметки не объединены, но поиском по имени оригинального автора их можно найти
Вписался несколько недель назад в марафон-контест от Яндекса — лекции по алгоритмам, задачки-домашки, и финальный этап, где за 3 часа нужно решить заключительный блок задач
Gmail впервые ввел концепцию ярлыков и тегов в апреле 2004 года, когда сервис и был запущен компанией Google
Powershell — язык весьма великодушный к программистам, почти всё в нём делается легко, интуитивно, и не требует особой подготовки и продумывания от автора кода
Спустя полгода после запуска велосипедика для автокачания и сохранения важных видосов, провёл аудит его работы и немного допилил

Сегодня расскажу о том, как можно применять Elasticsearch, Logstash, и Kibana для сбора и анализа информации в различных задачах системного администрирования и управления информационной безопасностью на предприятии...
Как я писал в одной из первых заметок цикла, ВК не позволяет полноценно выгрузить из себя пользовательские данные