
Тег: все эти ваши компьютеры
За годы использования восхитительного движка Эгея у меня накопилось множество микро-хотелок и потребностей в мелочах, которых в движке нет
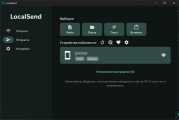
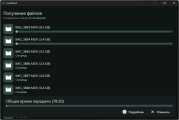
Зимой узнал про существование LocalSend — кроссплатформенного и open-source аналога AirDrop от Apple

В 2004-2005 годах я жил в центре Желдора, где (в отличие от окраинного Павлино) работала очень крупная городская сеть Интрателеком
Много лет покупаю для устройств в семье защиту от Лаборатории Касперского. Сначала обходился индивидуальными лицензиями, потом пришел к покупке больших бандлов — всё равно

Ящики на mail.ru были моими первыми электропочтами, и будучи старым рецедивистом-архивариусом, я сохранял доступы к ним до последних пор, хотя еще в нулевых перестал ими пользоваться для переписки


В 96-97 годах, благодаря победам на городских олимпиадах по информатике, я несколько раз ездил на ивенты и митапы в троицкий Байтик — хотя словов таких тогда в русских языках ещё и не существовало





Должен признаться, дорогой читатель: год назад, рассказывая о безвозвратном расставании с macOS я был не до конца честен с тобой
Много лет наблюдаю в приложении яндекс почты для iOS одну и ту же фичу: стоит выделить несколько писем от одного отправителя и попытаться удалить их, приложение предлагает баннером на полэкрана сделать

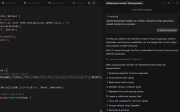


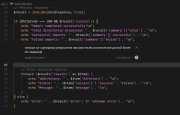

Последний месяц я провел в увлекательном взаимодействии с AI-средой для программирования, щас все расскажу...

Айтишная часть шарика продолжает рассыпаться паззлом: заметил на днях что через некоторых провайдеров очень долго открывается мой сайт




После переезда на виндовый ноут как основную личную машину на каждый день, распробовал сканер отпечатка пальца...

Позитивы выпустили большую статью на хабре про безопасность телеги
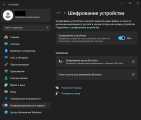
Один из вопросов, остававшихся после моей миграции с макоси — шифрование диска. У подданных племени тимкукового всё работает из коробки, и потеря устройства почти гарантированно обеспечивает вам защиту





В октябре 2017 года я купил себе первый мак, для того чтобы разобраться с этой экосистемой, влиться в стройные ряды и вообще красиво пить смузи в коворкинге модно пялясь в ретиновый экран
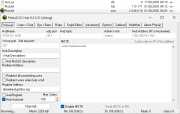
Через задачу типа «Удалённая установка программы» на windows-клиентах, покрытых Kaspersky Network Agent, удобно запускать инсталляторы или скрипты, выполняющие на хосте необходимые администратору настройки
В конце августа посетил конференцию OFFZONE 2024. Очень люблю вайб и информационную наполненность таких мероприятий, было и чему научиться, и чем развлечься

Классное выступление директора департамента информационной безопасности, Тинькофф Банк на Standoff 365
На днях по профильным ресурсам прогремела новость о серьёзной уязвимости в продуктах VMware. Думаю, а почему об этом не прилетела информация через RSS VMware Security Advisories
В прошлый раз я рассказывал, как победил самопроизвольную перезагрузку винды в производственной среде

Пару недель назад посетил «БеКон»— конференцию по безопасности контейнеров и контейнерных сред от производителя решений Luntry